Faster Elliptic Curve Point Decompression with Pre-Computed dlog table for square root
This refers to the problem that was faced using the deserialization of Banderwagon Curve Points, while implementation of the serialization and deserialization of Banderwagon Points was done, it was benchmarked alongside in comparison with the go-ipa and go-verkle implementation, and was found to be significantly slower. You can find the details in the blog
From the previous blog you can see that the performance difference was quite significant. Now if you don’t want to dive into the details then in summary it was caused by the following reasons
go-ipauses a precomputed dlog table over the tonelli-shanks algorithm to perform square root, which is needed for decompression of serialized point. This pre-compute optimization gives it a significant performance improvement over constantine based implementation as it was lacking- The benchmarking was done on a Apple Silicon M1 processor, which is based of ARM architechture. Now since Go has a runtime, it kindoff delivers very similar performace across different CPU architecture, whereas Nim doesn’t work like that, and relies on the native clang/gcc compiler. And constantine was designed by Mamy with assembly code for arithmetic operations built only for x64/x86 architecture, and doesn’t have support for ARM optimized assembly. This made the benchmarks significantly slower than
go-ipa
Now one of the problems have been solved, and the pre-compute optimization have been added. All thanks to Gottfried Herold for his implementation in gnark, which served as a reference implementation for me & huge thanks to Ignacio Haopin for his blogs. If you want to take a quick overview of the problem youself you can find all the resources and links below related to this problem and it’s solution
- Paper for Computing Square Roots Faster than the Tonelli-Shanks/Bernstein Algorithm Palash Sarkar - Nov’21
- The twitter discussion - Feb’23
- Tonelli-Shanks with Precomputed dlog tables by Ignacio
- Faster point decompression issue in Constantine - May’23
- Results from optimization by Ignacio
If you want to deep-dive into the the mathematics of the precompute optimization I would highly suggest to go through the blog by Ignacio mentioned above, you can find all the mathematical details there explained in a simple way
Our Optimization results
The following PRs contribute to the whole optimization achieved
- Adds the precomputed tables, and the modified tonelli-shanks algorithm to work with the precomputed values https://github.com/mratsim/constantine/pull/354
- Support for chainned field operation optimization https://github.com/mratsim/constantine/pull/356
- Removes the extra inversion operation for producing inverted square-root https://github.com/mratsim/constantine/pull/362
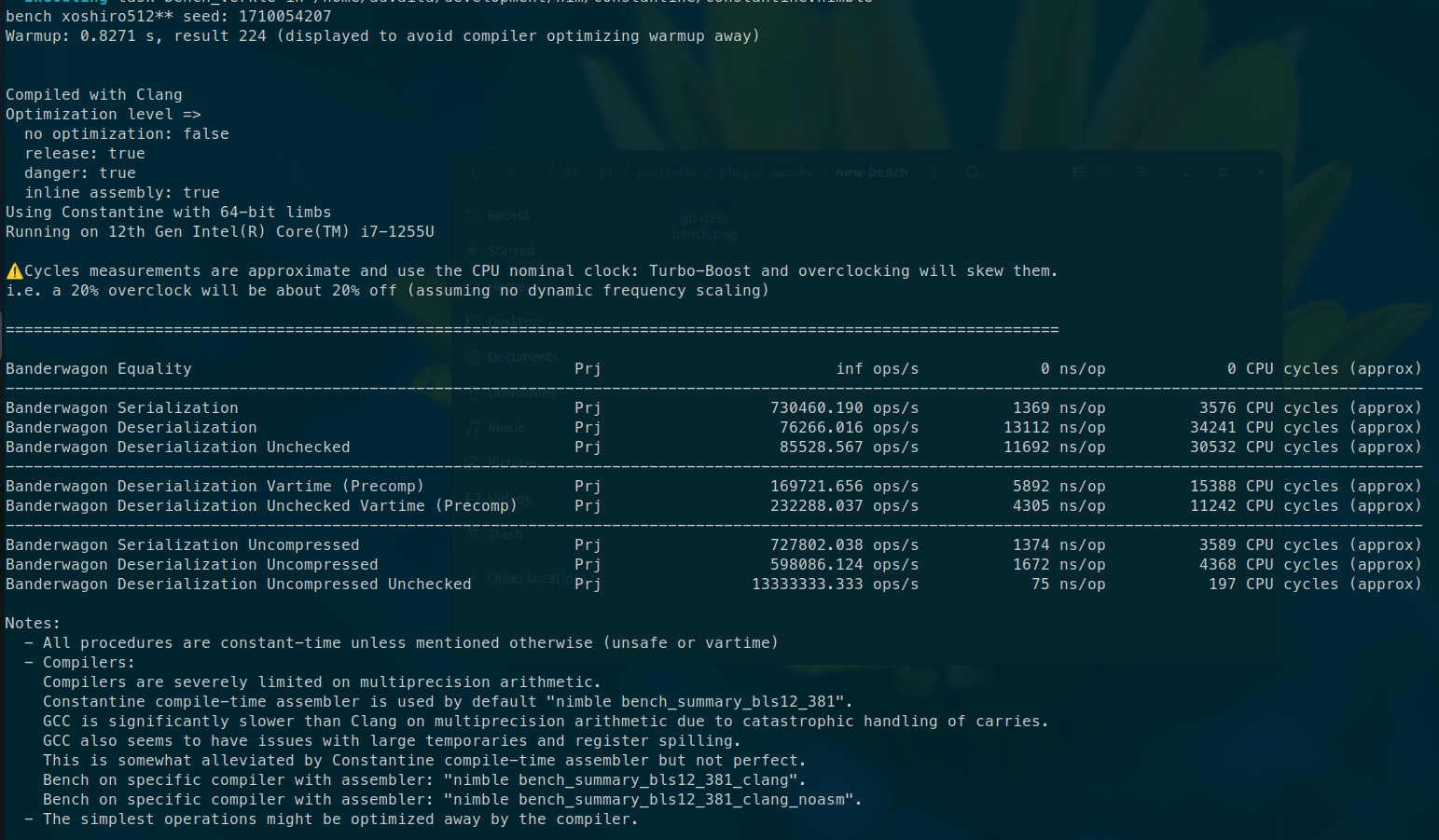
The following results were found opon testing in Ubuntu22 with Intel-i7-1255u, 16gb ram
| Benchmark Operation | Constantine Impl | go-ipa Impl | Remarks |
|---|---|---|---|
| Serialization | 1369 ns/op | 1960 ns/op | faster ✅ |
| Deserialization | 5892 ns/op | 9851 ns/op | 67% faster 🚀 |


Future Plans
The benchmarks achieved are pretty good, but one problem that remains for now is the implementation of the deserialization is not in constant-time arithmetics, since this is not a requirement for verkle, for now we are using vartime implementation of that, but the issue have been pin-pointed and described in detail in the following issue https://github.com/mratsim/constantine/issues/358, and we are looking forward to solve this in future. No fixed solution have been found yet, but we are looking in different directions to solve this problem. Also a sage script is suppoed to be added so that we can calculate the precomputed tables for different other curves which are currently added inside the constantine library, so that we can leverage this optimization for rest of the curves, currently only Bandersnatch and Banderwagon has this optimization working, since this was priotity for the Verkle trie work in Nimbus Eth1 Client